


The OpenSAFELY tech teams' work pipeline
- Posted:
- Written by:
- Categories:

As we mentioned in our introductory blog, the Product Team helps to manage a work “pipeline” that feeds work to the tech teams. In this post we’re going to tell you a bit more about how that works and how it’s changed over time.
Back in the early days of OpenSAFELY at the Bennett Institute, during the initial pandemic response, development work was prioritised largely based on instinct. This works really well when you’ve got a small and experienced team with good instincts! The tech team would choose what to work on next by discussing ideas within the team and producing a short document outlining a proposal, where details would be hashed out. Small groups would then work on delivering that proposal before moving on to the next thing. At this stage, we had a small team with a relatively small group of users, who they were working very closely with. However, it wasn’t going to scale as the team grew.
A new way of working
In early 2022 the tech team had grown rapidly and we had recruited a Director of Engineering and a Lead Product Manager, so we set about reorganising how we worked. We split into two teams, with the “Data Team” taking responsibility for the EHR data flowing through the system, and the “Pipeline Team” taking responsibility for the reproducible analytical pipeline that allows researchers to analyse that data without directly interacting with it. We also developed a “Work Pipeline” to help give transparency and a bit of structure to the prioritisation and delivery of our work and embed some Product Management approaches. When developing this Work Pipeline we leaned heavily on a series of great blogs by John Cutler.
Our Work Pipeline
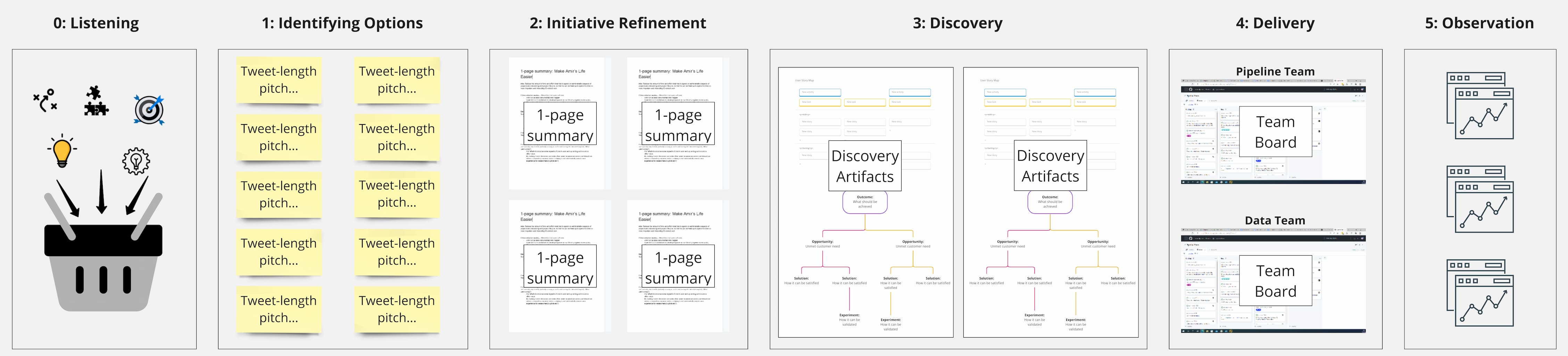
First, we keep a “bucket” of ideas for new capabilities, or changes to existing capabilities, that we might want to work on in future. It gives us a place to throw all those good ideas that we’d like to work on but can’t do right now. We can sift through the contents whenever we want to look for ideas to feed into the Work Pipeline.
We then have a series of stages, where each stage builds on the previous one. These are:
- Identifying options
- Refining options
- Discovery
- Delivery
As you move through these stages, the number of items under consideration decreases and the amount of detail increases. We also apply limits to the amount of “work in progress” at each stage, to force us to focus on high value work and minimise the cost of context-switching.
Finally, we continue to observe recently delivered initiatives to see if our work has had the impact we expected or not, to help us to reflect on if there is anything we could change or do differently next time.
Reflection and adjustments
Many aspects of this new way of working really helped us: especially limiting work in progress, pausing to do some Discovery with users prior to starting on Delivery, and observing initiatives after they were “done”. However, we came to realise that the teams weren’t split in the most optimal way, and we wanted to better align their responsibilities with coherent parts of the user journey. We are still experimenting with this, but have recently reorganised the teams into a “Reproducible Analytics Pipeline Team” (Team RAP) and a “Researcher Experience Team” (Team REX). When choosing to organise the teams in this way we were guided by (though didn’t necessarily follow to-the-letter) the Team Topologies approach.
We also wanted to give the teams more autonomy to choose what to work on to improve “their” parts of the user journey. Thus, we have asked the teams to bring their own initiatives through the Work Pipeline (following the processes we’d already been using, but with decision-making being held by the teams rather than leadership). This allows leadership to focus more on the big-picture direction.
It’s too early to say if these changes have helped, but we will keep reflecting and trying new things and perhaps write another blog to update you…