


As we’ve recently released version 1 of ehrQL, we thought we’d write a few words about how we test it. Or in other words: how can you as a user be confident that the queries you write will be correctly interpreted and return the expected results?
But first: some numbers…
As of v1, ehrQL’s codebase contains 9,481 lines of production code (along with 4,561 lines of comments), across 81 files. These include 199 class definitions, and 355 standalone functions.
To test this, we have a test suite of 2,399 tests, from 20,016 lines of code across 181 test files. We run this full suite of tests every time code is pushed to GitHub, and we aren’t able to merge code into our main branch unless all tests pass. It currently takes about ten minutes to run, but we’re able to easily run a subset of the tests locally for quicker feedback during development.
We also prevent ourselves from merging code that is not covered by a test. This doesn’t stop us writing buggy code, but it does mean that we have to think about testing every time we fix a bug or add a feature.
There are tests for every aspect of the project, including that we can generate the documentation, that our table definitions match those in the TPP and EMIS backends, that the command-line arguments are correctly parsed, that our test machinery works as expected… and much more.
However, one single test gives us more confidence that ehrQL code works correctly – that is, that users’ queries will return what they ought to – than all of the rest of the test suite put together.
This test is what we call a generative test. (More commonly, these are known as property-based tests.) Instead of specifying the behaviour of a single ehrQL query by giving specific examples (“when we run this query against that data, we expect these results”) we use a tool called Hypothesis to generate random queries, run these queries against random data in several different ways, and check that each gives the same results.
To explain how this works, we first have to explain the high-level architecture of the ehrQL interpreter.
One of the design goals of ehrQL is that, if two or more backend databases contain the same kind of data (such as clinical events from primary care) users should be able to write a single query that we can then run against each backend database.
Currently, we support running against databases in TPP (who use SQL Server) and EMIS (who use Trino). SQL Server and Trino both speak SQL, but the same kind of EHR data is structured differently in each backend, and each backend database speaks a different dialect of SQL, so we need to generate different SQL for each backend. We do this through first converting an ehrQL query to a kind of intermediate representation we call a query graph, and from this, we generate SQL.
For example, from a very simple ehrQL query like this:
dataset = create_dataset()
year = patients.date_of_birth.year
dataset.define_population(year >= 1940)
dataset.year = year
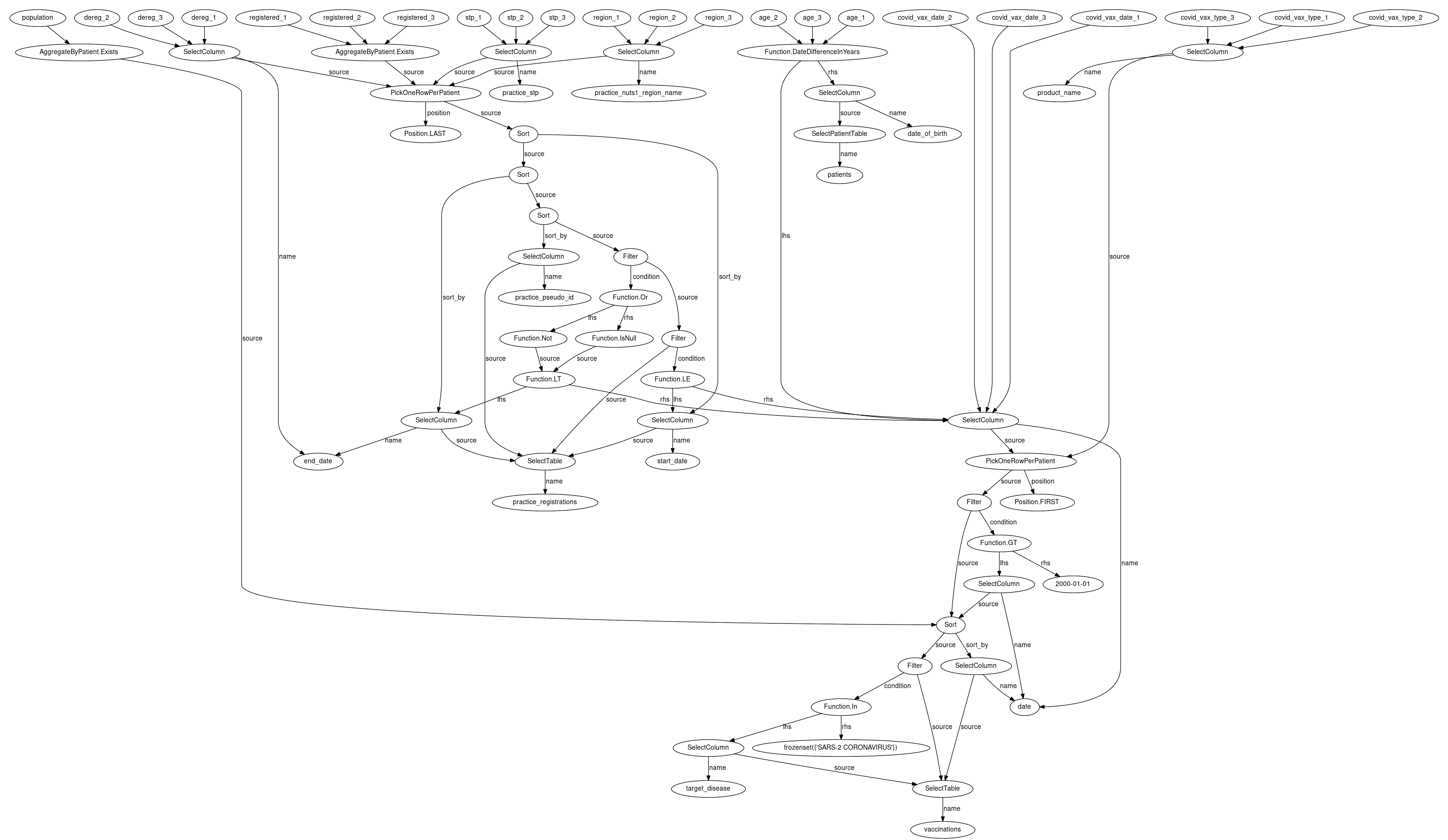
we generate a query graph that looks like this:

And from that graph, we can produce different SQL for each backend. Here’s the SQL for a simple test backend:
WITH cte_1 AS (
SELECT patients.patient_id AS patient_id
FROM patients
WHERE CAST(STRFTIME('%Y', patients.date_of_birth) AS INTEGER) >= 1940
)
SELECT cte_1.patient_id, CAST(STRFTIME('%Y', patients.date_of_birth) AS INTEGER) AS year
FROM cte_1
LEFT OUTER JOIN patients
ON patients.patient_id = cte_1.patient_id;
Generating the SQL involves an object we call a query engine. We have different query engines for SQL Server and for Trino, and most of the complexity (and so the potential source of most of our bugs) is in the implementation of these query engines.
For testing and development purposes, we have two additional query engines: a pure Python query engine and a SQLite query engine.
The pure Python engine is not designed to be efficient or to scale to millions of records, but it is designed to be simple and easy to reason about. And more importantly, because it is so different from the SQL query engines, any bugs it does have are likely to be different from the bugs those engines have – so we can use each to test the other.
The SQLite query engine, by contrast, shares a lot in common with the other SQL query engines. But it’s much faster and easier to work with locally and so can help quickly identify problems that are likely to also occur in the other query engines.
So: to test our query engines, we ask Hypothesis to generate large query graphs at random, ask it to generate random data, and then check that all four query engines give the same results to the same random query against the same random data.
We run the generative test for several hours every night, and when the test finds a query that produces different results across our query engines, the failure is reported to Slack.
This approach has found three categories of interesting bug.
Firstly, it has found bugs in our own logic.
Each feature we add to the query language has the potential to interact with every other existing feature.
Recent work to support passing a series to is_in() is an example – this is a complex feature to implement, and our work involved several iterations of attempting a solution, running the generative test for a few hours, understanding the error it found, and repeating.
Secondly, it has exposed our misunderstandings of the behaviour of the databases we work with. For instance, under some circumstances, SQL Server will reduce the precision of floats in a way that was surprising to us, and would be surprising to users. (For instance, it suggested that 0.5 + 0.25 = 0.8.) Having learnt this with help from Hypothesis, we were able to account for this in the implementation of ehrQL.
Thirdly, it has found a bug in Trino. Under certain circumstances Trino would get confused about whether 0.0 and -0.0 were the same number, leading to unexpected results. We reported this on November 20th, and a fix was merged on November 23rd. While the number of users directly affected by this is no doubt small, it’s a testament to the bug-hunting power of Hypothesis that it was able to locate such a subtle error.
Using Hypothesis at this scale was a new experience for us, and we now can’t imagine working on a project of this complexity without the confidence that Hypothesis gives us in the correctness of our code.
We hope that this description of part of our testing process also gives you, our users, confidence that your queries will be interpreted correctly and that they will return the results you expect.