


The ‘Five Safes’ Framework and applying it to OpenSAFELY
- Posted:
- Written by:
- Categories:
This article is part of a series: Output Checking
- The ‘Five Safes’ Framework and applying it to OpenSAFELY
- ‘Safe Outputs’ and Statistical Disclosure Control in OpenSAFELY
- The Opensafely Output Checking Service
- Running the OpenSAFELY Output Checking Service
The Fives Safes framework is a popular framework for designing safe and efficient data access systems that has been adopted by a range of Trusted Research Environments (TREs) across the UK. In this blog we describe what this framework is and how we have used it to inform the design of the OpenSAFELY platform. This blog is the first part in a series of blogs describing how we ensure patient information isn’t disclosed in OpenSAFELY research outputs.
What is the ‘Five Safes’ Framework?
The ‘Five Safes’ framework was originally developed to describe the Virtual Microdata Laboratory at the Office for National Statistics (ONS)1. It outlines data access as a set of five ‘risk’ dimensions that can be assessed independently, but should be considered jointly to evaluate the safety and efficiency of a data access system.
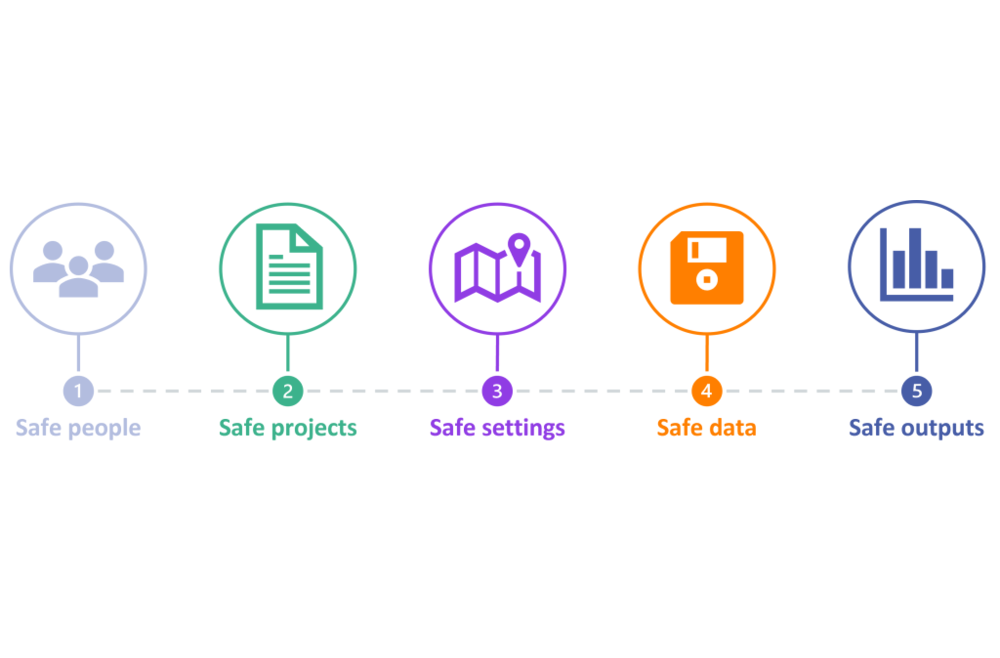
The Fives Safes are:
- Safe People — are the researchers using the data appropriately trained and aware of their role in data protection?
- Safe Projects — does the project make good use of the data? Is it lawful and, particularly for NHS data, in the public interest?
- Safe Data — what is the potential for individuals to be identified in the data?
- Safe Settings — are there technical controls on access to the data?
- Safe Outputs — is there any residual risk in outputs being released from the secure environment?
Below we will look at each of these in more detail and explore how the OpenSAFELY platform adopts and extends these principles.
Safe People
The first aspect of the Five Safes framework, Safe People, is aimed to define whether those who are undertaking research using confidential data are both trustworthy and have the technical skills to carry out their research successfully.
Many of the ways we ensure Safe People in OpenSAFELY are well established, and used widely in other secure research environments. As a minimum, to use the platform, all researchers must be an accredited researcher via Safe Researcher Training provided by the ONS or the UK Data Service. This training is designed to develop good practice around safe data use in a wide range of settings, and is the most common accredited research programme for research environments in the UK 2. Topics covered in the training include data security and personal responsibility when using confidential data, as well as the approaches to assessing the risk of disclosure of personal information from research outputs and techniques for reducing this risk, known as Statistical Disclosure Control (SDC).
In addition, all users sign a Data Access Agreement, promising to use data in line with the OpenSAFELY policy for researchers, which outlines expectations around data sharing.
Beyond these standard requirements, we also require users to prove that they have the correct technical skills to use OpenSAFELY. The design of the platform requires a way of working that is often new to users, but that we believe ensures best practices around open sciencee and ultimately maximises the utility of the data OpenSAFELY allows access to. These requirements include:
- Confirmation of an understanding of how OpenSAFELY works, which can be gained from reading our documentation and completing our getting started guide.
- Evidence of existing knowledge and skills working with Electronic Health Records (EHRs).
- Track record of high quality research.
- Strong computational data science skills including version control, git, and GitHub (and evidence of reproducible code more broadly through existing open, well documented code).
Beyond the application, we also provide thorough documentation on all aspects of the OpenSAFELY platform, which combined with our co-pilot programme, ensures users fully understand how to use the platform safely and effectively and encourages collective responsibility.
Safe Projects
The Safe Projects aspect of the Five Safe framework considers the legal, moral and ethical considerations surrounding the use of data. This typically involves restricting the amount of data made available for a project to the minimum amount that allows statistically valid analysis whilst providing maximum public benefit. The OpenSAFELY platform does not give researchers unconstrained access to view all data available on the platform (you can see the data sources here). All projects must first go through an application process before access is granted by NHS England (the Data Controller). Most importantly, this application process assesses a project’s purpose — the reasons why a project is making their data access request. This includes what questions the project hopes to answer, why OpenSAFELY is needed to answer them, the methods the project will use and the expected outputs of the project. This has several main benefits:
- Firstly, this ensures that the data available in OpenSAFELY can be used to satisfy this purpose; and if it can, defines which of the many linked datasets available are required to complete the project.
- Secondly, this also verifies that the project purpose is aligned with a lawful basis for data processing by OpenSAFELY; in OpenSAFELY this basis is provided by the Control of Patient Information (COPI) notice issued by the secretary of state for COVID-19 related work.
- The project application also confirms that appropriate ethical approval has been gained for the proposed research. This is important, as we believe the questions being asked should not harm individuals, groups of individuals, the notion of research or lead to unfair distribution of resources. As the research in OpenSAFELY involves processing confidential information of patients or service users outside of the care team without consent, all research studies have to provide a reference from the Health Research Authority’s NHS Research Ethics Committee (REC). Finally, for any projects categorised as service evaluation or audit (see this table for details of the different characteristics of research, service evaluation, audit and health surveillance projects), a senior sponsor is required. By requesting sponsorship from senior leaders in the health system, who vouch for the appropriateness and utility of the study using their experience and knowledge, we can focus on how limited resources in research and software developer skills are deployed, especially in times of crisis such as the COVID-19 pandemic.
- The project purpose also provides an opportunity to give a lay description of the project. We believe the patients whose data we use should be provided with the resources to understand how their data is used; all lay summaries of approved OpenSAFELY projects are made publicly available.
Once a project application is submitted, it is first reviewed by the OpenSAFELY Information Governance team to make sure it meets the criteria above. Following this, it is reviewed by NHS England from a legal perspective, judging whether the project has been categorised correctly (does it meet a COVID-19 purpose and has it been correctly identified as either research, service evaluation or audit). Only following this approval can a project officially begin. You can see a list of all previously approved projects, with their statement of purpose on this page.
Safe Settings
Safe Settings refers to any technical controls that are applied to data access to prevent both accidental and deliberate disclosure of confidential data. The OpenSAFELY TRE model aims to substantially exceed, by design, the current requirements on securing sensitive healthcare data in line with the GDPR principles of data protection.
In OpenSAFELY, this starts before researchers have any access to patient data. Using the OpenSAFELY framework, researchers can begin to specify their study in code before being given data access. This forces researchers to think carefully about processing only the data they need, supporting the GDPR principles of purpose limitation and data minimisation. This code can then be run against dummy data generated using the OpenSAFELY framework, allowing error testing before the code is run against real data; this supports the GDPR principle of integrity.
Once researchers are ready to run analyses on real patient level data, there are several principles we implement to ensure a Safe Setting. Most importantly, OpenSAFELY does not transport any patient level data; instead, it allows researchers to run analyses on the EHR data it provides access to, in situ within the secure servers of the EHR providers themselves. This is a drastic improvement on current practices where cuts of patient level EHR data are downloaded for individual use. On top of this, OpenSAFELY uses a tiered level of security that limits the number of people who have access to the raw EHR data to a minimum. This is described more fully in our documentation but briefly, there are 4 levels:
- Level 1 — This level provides access to the raw EHR data. Only developers working at the EHR providers themselves have access to this level of data, so they can continue to process this data for GPs for use in routine care.
- Level 2 — This level provides access to the pseudonymised versions of the data available in level 1, produced and updated each week by the EHR vendors for the OpenSAFELY database. Only a small number of OpenSAFELY engineers have access to this level of data, to enable development of the OpenSAFELY platform.
- Level 3 — This level provides access to analysis ready extracts of the data available in level 2. These extracts are initiated by OpenSAFELY users, but importantly, as the data available at this level is still patient-level, access to this level is similarly restricted to a small number of OpenSAFELY staff to allow data quality assessment.
- Level 4 — This level provides access to aggregated study results for OpenSAFELY users. This is the only level of data these users can access; researchers do not have unfettered access to the raw patient data and only see the outputs of their statistical results, which satisfies the GDPR principle of confidentiality. Access to this level is secured via VPN access to a remote desktop. No results are released from the secure environment without undergoing dual independent checking for disclosure issues (see the Safe Outputs section below).
Beyond access controls, OpenSAFELY also provides a Safe Setting through transparent working practice. Logs of all the analysis code run against patient level data are publicly available . Similarly, all the analysis code that is run is made publicly available, at a maximum of 1 year after it is run, if not immediately. This satisfies the GDPR principles of lawfulness, fairness and transparency.
Safe Data
The OpenSAFELY platform allows access to the full pseudonymised primary care records of over 58 million people in England, linked to additional sources of person-level data: this level of detail is incredibly powerful and has allowed important analyses to be performed to inform the COVID-19 response. Despite all of the controls discussed so far, the granularity of EHR data is inherently unsafe; it contains individual patient level data that could be used to identify individuals. Safe Data refers to minimising the risk of an individual being identified in the data being provided, which OpenSAFELY achieves using several controls.
Firstly, as is standard practice when working with patient level data, any direct identifiers are removed and any indirect identifiers are pseudonymised (we’ll discuss what this means and why it is not enough in a later blog). This control is applied to level 2 data in the tiered system discussed above.
Secondly, access to the patient data is controlled through a set of curated, pre-specified variables. Researchers can not run arbitrary queries against the patient level data, but are instead restricted by these variables. This also contributes to ensuring Safe Projects, as at the point of project application, we can see if a question can be answered using these variables. Beyond ensuring Safe Data, this also makes the project code robust and reproducible.
The final control is the tiered security model discussed above. By allowing researchers to run their analysis on psudoymised patient level data (“level 3 data” in the tiered system above) but restricting view access to only aggregated results (“level 4 data”), we reduce the possibility that an individual could be identified in the processed data.
Safe Outputs
Having applied all of the controls above and produced analysis results, the Safe Outputs dimension describes the residual risk that exists in these outputs. Even in aggregated study results there is a risk that patients could be identified.
In remote research environments such as OpenSAFELY, this can be achieved by checking any research outputs before they are released from the secure environment. In line with other remote research environments, OpenSAFELY applies a set of controls on any research outputs before they are released and made publicly available. This will be the topic of the following blogs in the series, but briefly this involves dual independent checking of any outputs before they are released by researchers training in SDC.
Conclusion
The Five Safes framework has become the dominant model for providing safe, efficient data access. Some of the principles are well established: the Safe People, Safe Projects and Safe Outputs controls applied in OpenSAFELY are not unique. However, taken together we believe the Safe Data, and Safe Settings controls applied in OpenSAFELY improve on the industry standard and provide a framework that can be built upon by other TREs.