


Generating data on the NHS England Core20PLUS5 inequality groups using OpenSAFELY in GP records
- Posted:
- Written by:
- Categories:

In order to tackle health inequalities NHS England have recently launched the “Core20PLUS5” initiative to help local areas identify and reduce inequalities across key areas:
- Core20 - the most deprived 20% by IMD quintile nationally.
- PLUS - groups deemed at risk of health inequalities, defined locally by ICS.
- 5 - defined clinical areas requiring accelerated improvement; maternity, severe mental illness, respiratory disease, early cancer diagnosis, and hypertension case-finding.
In this blog, we describe the reusable code, logic and concepts that already exist in OpenSAFELY and are available for re-use by all researchers to incorporate Core20PLUS5 groups into their analyses.
This is a work in progress, some sections are incomplete and will be released in the following weeks. This is not laziness, this is an agile approach! We believe in sharing our work and code early, getting feedback from users, and building our tools iteratively through pooling the skills of our team at OpenSAFELY including software engineers, clinicians, epidemiologists, and researchers.
We also think it’s helpful to share this kind of deeper technical work, so that everyone across the community can see how EHR data is used: patients might find it interesting; people in adjacent technical communities might find ideas to re-use; funders can see the important complex work that is done prior to the final regression analyses; NHS analysts who are more familiar with secondary care data can get a window into primary care data; and potential collaborators can contribute to this growing open source codebase.
This is the first iteration of a library of variables which can be used to rapidly break down datasets into the Core20PLUS5 groups. We hope this will allow easy identification of inequalities relating to health outcomes, processes, or prescribing. Researchers have diverse requirements depending on their study aims, so it is not possible to define a single variable which covers all use cases, nor to list many variables which cover every possible scenario. Instead, we aim to design variables for typical use cases, which researchers may adapt to meet their specific needs.
In OpenSAFELY we have built a set of pragmatically standardised approaches and tools for common data curation tasks when working with NHS EHR data. This improves efficiency, as all new users can see all prior user’s data curation code; quickly understand it; and then re-use it, or modify it.
Contents
- Core20 - The most deprived 20% of the national population
- PLUS - Patient groups deemed likely to experience health inequalities
- Ethnic minority communities
- People with learning disabilities and/or autism (in development)
- Coastal communities with pockets of deprivation (in development)
- People with multi-morbidities (in development)
- Protected characteristics
- Age
- Further characteristics in development
- Inclusion health groups (scoping phase)
- 5 - Key clinical areas with known health inequalities
- Maternity (awaiting prioritisation)
- Severe mental illness (scoping phase)
- Respiratory disease (awaiting prioritisation)
- Early cancer diagnosis (not queued)
- Hypertension case-finding (awaiting prioritisation)
Core20 - The most deprived 20% of the national population
Deprivation
Background
The most deprived geographic areas face the worst healthcare inequalities in relation to healthcare access, experience, and outcomes - for example the Marmot Review identified people living in the poorest neighbourhoods on average die seven years earlier than people living in the richest neighbourhoods.
Definition
The Core20 principle suggests that the most deprived 20% of the national population should be targeted to reduce healthcare inequalities, as identified using the Index of Multiple Deprivation (IMD). The IMD ranks areas in England from most to least deprived based on a combination of seven different factors:
- income
- employment
- education
- health
- crime
- barriers to housing and services
- living environment
The NHS data dictionary does not define deprivation within its coding standards.
Codelists
Not applicable.
Variables
An IMD rank associated with each patient can be extracted as a variable in OpenSAFELY. The IMD rank is determined based on nationally published IMD rankings, which break down IMD by Lower Super Output Area (LSOA) - geographic areas containing approximately 1500 people, or 650 households.
In the example below, the address_as_of() method is used to return an integer representing the IMD rank of the LSOA which the patient lives in - this integer is stored in a variable named ‘imd’. In a further step, a variable named ‘imdQ5’ is created, which ranks each ‘imd’ variable into a quintile (1st quintile being most deprived, and 5th quintile being least deprived) to simplify output interpretation.

Research example
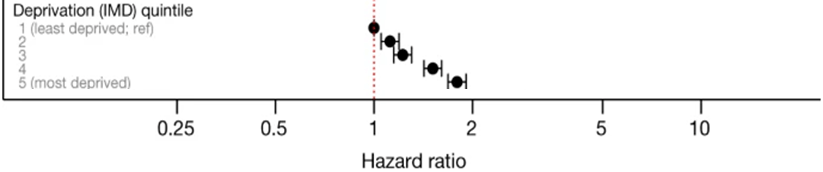
The following paper shows an example where a deprivation variable was used in OpenSAFELY, to test for differences in COVID-19 related death between deprivation quintiles.
- Title: Factors associated with COVID-19-related death using OpenSAFELY
- DOI: https://doi.org/10.1038/s41586-020-2521-4
- Figure showing hazard ratio for each deprivation quintile in relation to COVID-19-related death:
Strengths and limitations of this curation approach
- It is possible to attribute an LSOA (and therefore IMD rank) to almost all patient records, with very little incompleteness in this data.
- To ensure individual LSOAs cannot be identified, the original ranking is rounded to the nearest 100 in the OpenSAFELY database. This results in the loss of some granularity, but should not be problematic for most analyses.
- The current approach in OpenSAFELY uses IMD ranks, which reveal how relative differences in deprivation between areas nationally are linked to health outcomes. For some research purposes it may be desirable to understand how differences in absolute deprivation are linked to health outcomes - assessed from raw IMD scores. OpenSAFELY does not currently extract raw scores, following data minimisation principles to reduce disclosiveness - this could be reviewed if strong use-cases for the raw scores emerge.
- The IMD quintile method described above produces a relative national ranking. Analyses at a lower geographic level may be adapted to provide results using relative local IMD percentiles.
- English indices of deprivation are recalculated every 3 to 4 years, however, the factors underpinning IMD scores change continually. So depending on the time-periods of interest in a study, the IMD score can be ‘out of date’ and a poorer predictor of actual deprivation for the time-period being assessed.
- LSOAs are updated once every 10 years. The current LSOAs may not represent changes to local areas which have occurred since the last update.
PLUS - Patient groups deemed likely to experience health inequalities
Ethnic minority communities
Background
Health inequalities exist between ethnic groups. The picture is complex, with the inequality varying both between different ethnic groups and across different conditions. For example, we have found the COVID-19 pandemic had a disproportionate impact on ethnic minority communities, who experienced higher infection and mortality rates than the White population.
Definition
The NHS Data Model and Dictionary states that ethnicity categories from the 2001 census are currently the standard across the NHS however we know that other standards are used day to day to record ethnicity (e.g. 2011 census). OpenSAFELY allows users to ascertain ethnicity based on their own definition.
Codelists
Several codelists have been developed by the OpenSAFELY collaborative related to ethnicity, users should select the codelist(s) appropriate for their analysis purpose. Note that some codelists relating to ethnicity contain terms which are offensive. Although these terms are outdated and no longer in routine use, it is necessary to include them in codelists due to the historic nature of the data that is being analysed. Excluding these terms would reduce the completeness of the data and may mean that more people are not identified with an ethnicity in analyses.
Variables
The codelists referred to above can be used to define an ‘ethnicity’ variable, as seen in the example below:

Using OpenSAFELY this variable is extractable from Electronic Health Records, and output can be grouped into either 5 or 16 ethnicity categories (based on categories defined in the 2001 census), with an additional ‘unknown’ category in both cases.
Example of use in research
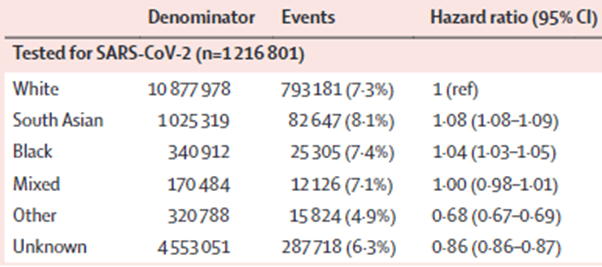
The following paper shows an example where an ethnicity variable was used in OpenSAFELY, to test for differences in COVID-19 related outcomes between ethnicity categories.
- Title: Ethnic differences in SARS-CoV-2 infection and COVID-19-related hospitalisation, intensive care unit admission, and death in 17 million adults in England: an observational cohort study using the OpenSAFELY platform
- DOI: https://doi.org/10.1016/S0140-6736(21)00634-6
- Table showing associations between ethnicity and testing positive for COVID-19 in wave 1 of the pandemic:
Strengths and limitations of this curation approach
- OpenSAFELY-TPP has information from the primary care record and also from the Secondary Uses Service (SUS) which contains data entered from hospitals. When both are included ethnicity status can be obtained in approximately 91% of patients.
- Ethnicity is self-defined by the individual, based on their identification with a group of people with whom they share attributes and behaviours, e.g. traditions, culture, history, language. However information may not always be entered into the health record by a patient which may lead to discrepancies in recording.
- The ethnicity categories defined in the OpenSAFELY platform utilise the categories from the 2001 census in accordance with the NHS data dictionary, but slightly different categories have been defined in the 2021 census. In some cases this may lead to the ethnicity of some patients not being represented exactly in line with the patient’s intention.
- Gypsy, Roma, or Irish Traveller ethnicities are not currently identified as distinct categories in OpenSAFELY output (where the 2001 census grouping is used), but NHS England has suggested that people in these communities are at risk of inequalities. Users can still identify these ethnicities by creating a new codelist.
- Searches in OpenSAFELY typically join the latest recorded ethnicity (at the time the study is run) to older data in order to minimise computational resource burden. As ethnicity is typically a stable characteristic, it is usually a reasonable assumption that the latest ethnicity reflects ethnicity over the long-term. However, ethnicity is a self-defined social construct, and a person may change their ethnicity over time. It has been found that approximately a third of patients with multiple contacts (as an inpatient, outpatient or A&E attendee) had inconsistent ethnicity codes in their records, suggesting inconsistencies with how patients self-report (and/or how healthcare staff record) ethnicity.
Protected characteristics
Background
Protected characteristics are described by the Equality & Human Rights Commission as characteristics which it is against the law (as per the Equality Act 2010) to discriminate against someone on the basis of. They include:
- Age
- Disability
- Gender reassignment
- Marriage & civil partnership
- Maternity
- Pregnancy
- Race
- Religion or belief
- Sex
- Sexual orientation
Some of these characteristics are expected to directly affect several health outcomes through unavoidable biological processes, e.g. ageing. However if discrimination against these groups is creating inequalities in service provision, then this would cause inequality in health outcomes beyond what is expected.
Age
Definition
Age is conventionally expressed in years as per NHS Data dictionary standards.
Codelists
Specific codelists are not needed to identify age in the OpenSAFELY platform.
Variables
Age is available as a variable in OpenSAFELY, by using the method age_as_of(). In the example below a variable named ‘age’ is created, which is an integer representing age in years for each patient at the specified date.

Example of use in research
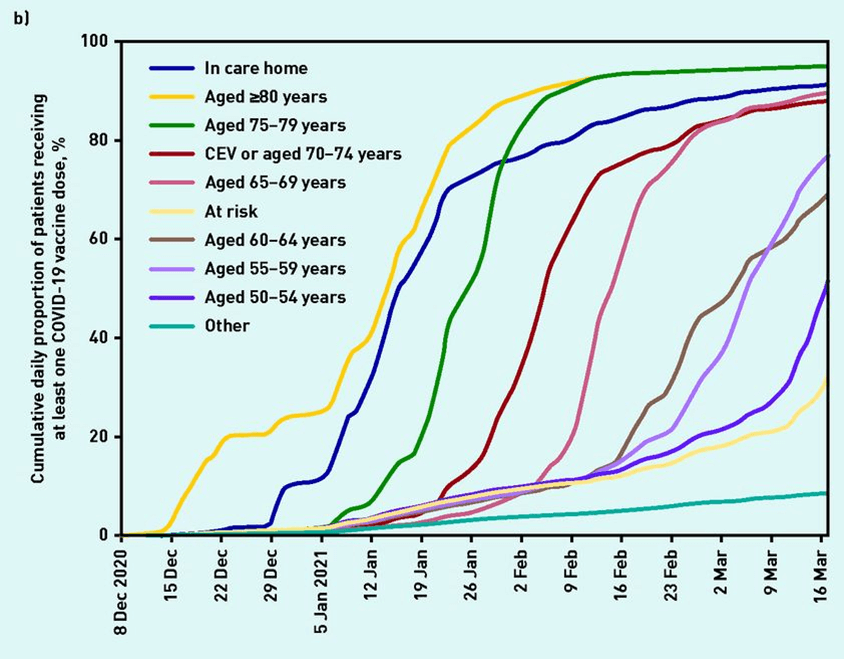
The following paper shows an example where an age variable was used in OpenSAFELY, to test for differences in COVID-19 vaccination uptake between age bands.
- Title: Trends and clinical characteristics of COVID-19 vaccine recipients: a federated analysis of 57.9 million patients’ primary care records in situ using OpenSAFELY
- DOI: https://doi.org/10.3399/BJGP.2021.0376
- Figure showing COVID-19 vaccination uptake in various patient groups, including age band:
Strengths and limitations of this curation approach
- In our experience, age is rarely inaccurate or missing in the medical record, although we have not yet formally assessed accuracy or missingness.
- Researchers may group age-bands in various ways to aid pragmatic analysis, this involves subjective judgement. Age-bands should be sufficiently narrow to avoid age-related inequalities being hidden within an overly wide age-band, and should take into consideration whether age-related inequalities are suspected around particular ages for the dependent variable.
- Note that the patient’s date of birth is rounded down to the first of the month, and age is derived from this rounded date.